To facilitate native SQL code we have stored procedure support in Azure Data Factory (ADF). When we work with stored procedures, mostly we use input parameters, however, a stored procedure can also have output parameters. In this case, we need to deal with return values, similar to how a value is returned by a function. This article will describe how you can work with stored procedure output parameters in ADF.
ADF has the SQL Server Stored Procedure Activity, which is used for any stored procedure you have in a SQL Server database. ADF also has a Lookup activity in which you can use a stored procedure. The example will use the Lookup activity to execute a stored procedure in a database.
Let's start by creating a stored procedure (SP) with an output parameter:
CREATE PROCEDURE [ETL].[sp_testprocOutParm]
(
@input VARCHAR(10),@Iambit BIT OUTPUT)
AS
BEGIN
IF @input >= '1'
BEGIN
SET @iambit = 1;
RETURN;
END
END;Let's see if the SP returns the expected value. Well, how do we execute the SP in SQL Server Management Studio (SSMS)? Please write below syntax to find the outcome.
DECLARE @Iambit bit EXEC ETL.sp_testprocOutParm '1', @Iambit OUTPUT SELECT @Iambit Iambit
You should have outcome like below Fig 1.
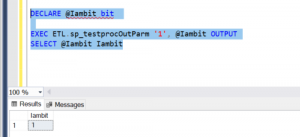
Fig 1: Execution of output parameter in SSMS
The SP is created in the database and it has returned the expected outcome. Now we need to move to ADF.
This article assume you know how to add Lookup activity to ADF pipeline. In your pipeline get the Lookup activity as like figure 1.1.Now, Go Settings of the Lookup activity and choose stored procedure from theUse query selections (as shown in Figure 2). Then you should able to see the stored procedure under the dropdown list which you just created in the database. If you are not able to see the stored procedure then it most likely a problem with your access in ADF. Please remember, though you can execute the SP in SSMS, this doesn't mean you will have access to the stored procedure from ADF, You will need to talk with your portal admin and find out if your user has been given enough permissions to execute the stored procedure.
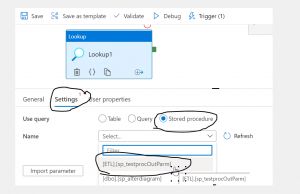
Fig 2: Connect stored procedure via Lookup in ADF
If you find out the stored procedure in the list, you can continue to the next step. The next step is to import parameters by clicking the button, import parameter, as shown in Fig 3.
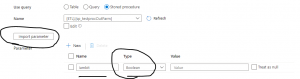
Fig 3: import parameter
The import parameter will load all the SP parameters, both input and output parameters. In this case the single output parameter will be shown. Having an output parameter means you want to return some value from the stored procedure and use it in ADF. In this example, the return value will control the next activities in the pipeline. Let's store the return value into a variable.
Drag and drop the Set Variable activity and connect it with the with the Lookup, as shown below in Fig 4

Fig 4: Add Set variable
We need a variable as shown in Fig 5, put variable name and select type of the variable. Since variable is at pipeline scope, so make sure you have selected pipeline itself not any activities in the pipeline.

Fig 5: Creating variable
While creating variables, you will find there are three types of variables: string, Boolean and Array. We have chosen Boolean type for the variable since our stored procedure returns Boolean.

Fig 6: Creating variable
Now, let's get to the pipeline and select 'set variable' activity (as shown in Fig 7). In the Set variable activity, please click the variable tab. Here is where you will find the recently created variable under the name drop down. Select it, as shown in Fig 7.
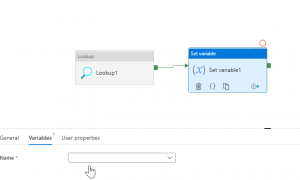
Fig 7: Choose the variable
To bind the value returned from the stored procedure to the variable, you need write the expression under the 'value' of the variable, as shown in Fig 8

Fig 8: expression to hold return value
The expression to bind return value from stored procedure is:
@activity('Lookup1').output.firstRow.IambitLet's explain what expression means. The above expression will return first row from the lookup activity, named Lookup1, and return the column name from the stored procedure, which is 'Iambit'. Here, 'Iambit' will return the result as 1 (a Boolean TRUE).
Be Cautious: Though the variable is set to be Boolean and the stored procedure returned the value as a bit, I found an error in the ADF with the above expression. I had to modify the expression to explicitly convert the return value to Boolean, like the code below:
@bool(activity('Lookup1').output.firstRow.Iambit)In summary, output parameter in stored procedure a great facility when in need and happy to see that works in ADF. Please note that, the example we depicted here in this article by using very simple stored procedure, however; in business scenario your stored procedure could be a bit complex. For example, you may have logging tables in the data warehouse and you want any activity in ADF will only execute when you pass particular pipeline name as input parameter as a return if the stored procedure returns TRUE.