Continuous Integration and Continuous Deployment (CI/CD) are integral parts of the software development lifecycle. As a Data Engineer/ Data Professional when we build the ETL pipeline using Azure Data Factory (ADF), we need to move our code from a Development environment to Pre-Prod and Production environment. One of the ways to do this is by using Azure DevOps.
Target Audience:
This article will be helpful for below mentioned two types of audiences.
Audience Type 1: Using DevOps code repository in ADF but CI/CD is missing
Audience Typ 2: Using ADF for ETL development but never used DevOps repository and CI/CD
For Audience Type 1 you can follow the rest of the blog to implement CI/CD. And for audience type 2, you need to first connect ADF with the DevOps repository, and to do so please follow this blog post and then follow the rest of this blog post for the CI/CD.
This blog post will describe how to set up CI/CD for ADF. There are two parts to this process one called 1) Continuous Integration (CI) and 2) Continuous Deployment (CD).
1) Continuous Integration (CI)
First, you need to log in to the Azure DevOps site from your organization and click the pipelines as shown in fig 1.
Fig 1: DevOps pipelines
And then click “New pipeline” as shown in fig 2

Fig 2: New pipeline creation
And then follow the few steps to create the pipeline:
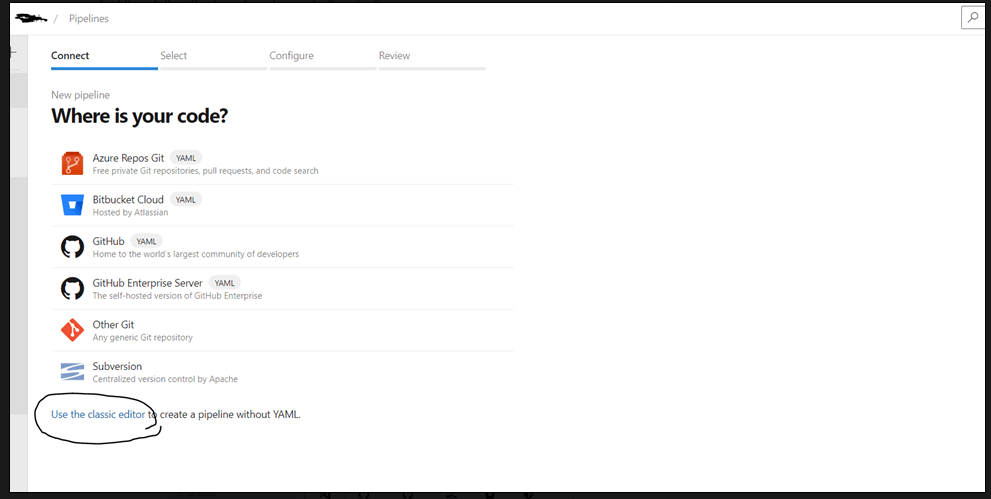
Step 1: Depending on where your code is located, choose the option. In this blog post, we are using the classic editor as shown below in fig 3.
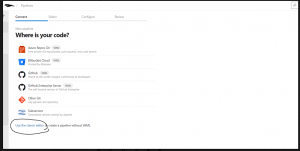
Fig 3: Choose the right source or use the classic editor
Step 2: In this step, you need to choose the repository that you are using in ADF and make sure to select the default branch. We have chosen ADF_publish as a default branch for the builds.
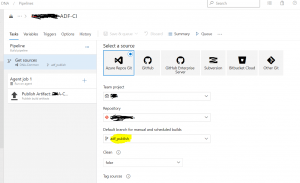
Fig 4: selecting the branch for the pipeline
Step 3: Create an Empty job by clicking the Empty job as shown in below figure 5
Fig 5: Selected Empty job
Step 4: You need to provide the agent pool and agent specification at this step. Please choose Azure Pipelines for the agent pool and windows latest for the Agent specification as shown in figure 6.
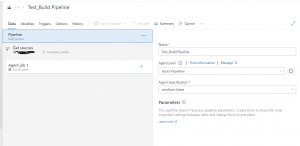
Fig 6: Agent pool and Agent specification
Now click "Save and Queue" to save the build pipeline with the name “Test_Build Pipeline” as shown below figure:
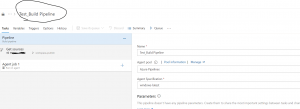
Fig 7: Saved the build pipeline
The build pipeline is completed, and the next part is creating the release pipeline which will do the continuous deployment (CD) means the movement of the code/artifacts from Development to the pre-prod and Production environment.
2) Continous Deployment (CD)
The very first step of Continuous Deployment is to create a new release pipeline. And this release pipeline will have a connection with the previously created build pipeline named "Test_Build Pipeline".
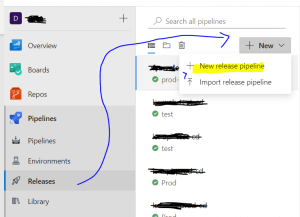
Fig 8: Release Pipeline
As soon as you hit the new release pipeline following step will appear. Please close the right popup screen and then click +Add on the artifact as shown below figure:
Fig 9: Create the artifact
Next step to connect the build pipeline and the release pipeline, you will find out the build pipeline that you created at the CI process earlier and choose the item “Test_Build Pipeline”
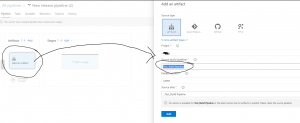
Fig 10: connecting the build pipeline from the release pipeline
Click on Stage 2 and select an empty job as shown in fig 10
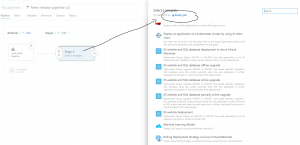
Fig 11: Empty job under release pipeline
After the last steps the pipeline will look like the below, now please click on 1 job, 0 tasks. We need to create an ARM template deployment task
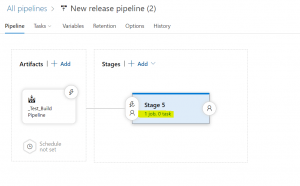
Fig 12: Release pipeline job and task
Search for ARM template deployment, as shown in fig 13. ARM template Deployment task will create or update the resources and the artifacts e.g. Linked services, datasets, pipelines, and so on.
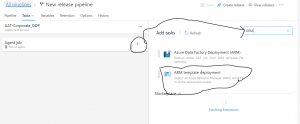
Fig 13: search for the ARM template
After adding the ARM template, you need to fill in the information for 1 to 12 as shown in the below diagram:
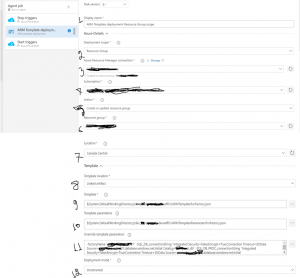
Fig 14: ARM Template information
- Display Name: Simply put any name to display for the deployment template
- Deployment Scope: You have options to choose the deployment scope from Resource Group, Subscription, or Management Group. Please choose Resource Group for ADF CI/CD.
- Azure Resouce Manager Connection: This is a service connection; if you already have a service principal you can set up a service connection or create a completely new one. The Cloud Infrastructure team in your organization can set it up for you. You will also find details about Service Connection in Microsoft Learn.
- Subscription: Please choose the right subscription where the resource group for the ADF instance resided for the pre-Prod or Production environment.
- Action: Please Choose "Create or Update resource group" from the list.
- Resource Group: The resource group name where the ADF instance is lying.
- Location: Resource location e.g. I have used Canada Central
- Template Location: Please choose either "Linked Artifact" or "URL of the file". I have chosen "Linked Artifact" which will connect the ARM template which is already built via Continuous Integration (CI) process.
- Template: Please choose the file "ARMTemplateForFactory.json"
- Template parameters: Please choose the template parameter file: "ARMTemplateParametersForFactory.json"
- OverrideTemplate Parameters: Make sure to overwrite all the parameters including pre-prod or production environment's database server details and so on. Go through all the parameters that exist in the Development environment you need to update those for the upper environments.
- Deployment mode: Please choose "Incremental" for the Deployment mode.
After putting all the above information please save it. Hence your release pipeline is completed.
However, to make this pipeline runs automated, means when you push the code from the master to publish branch you need to set up a Continuous deployment trigger as shown in fig 15
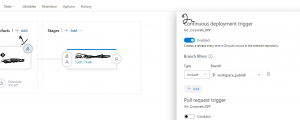
fig 15: Continuous deployment Trigger
The last step of the CD part is creating a Release from the Release pipeline you just created. To do so please select the Release pipeline and create a release as shown in fig 16.
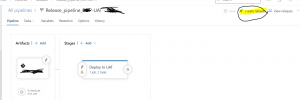
Fig 16: Create a Release from the release pipeline
You are done with CI/CD. Now to test it please go to your ADF instance choose the master branch and then click the 'Publish' button as shown below in figure 17. The C/CD process starts and the codes for pipelines, Linked Services, and Datasets move from the Development environment to Pre-Prod and then to Production.
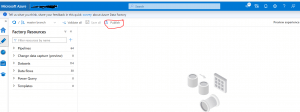
Fig 17: Publish from Azure Data Factory (ADF)
The blog post demonstrates step by step process of implementing CI/CD for ADF by using ARM templates. However, in addition to ARM template deployment; there is another ARM template named "Azure Data Factory Deployment (ARM)" which can also be used to implement CI/CD for ADF.