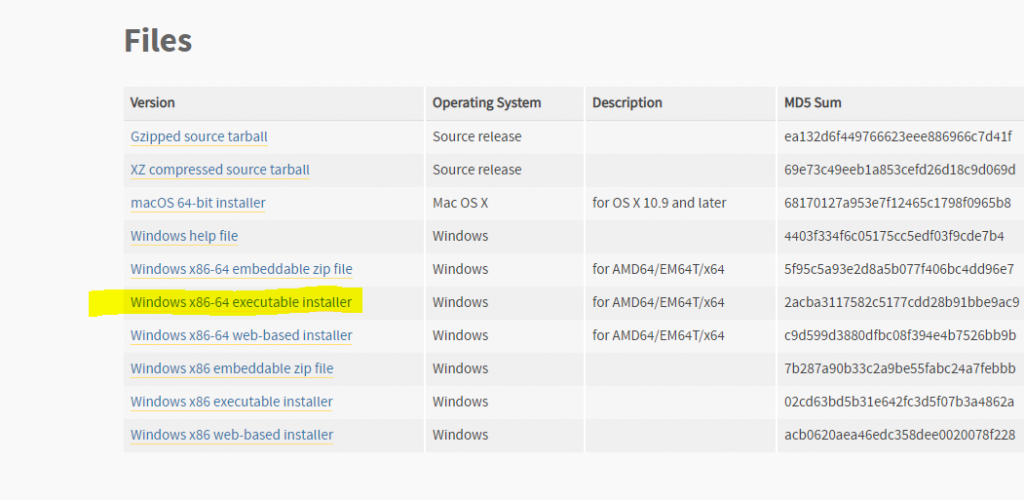
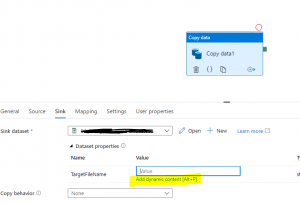
There are two ways you can develop and execute code in Azure Synapse Studio:
- Synapse live development
- Git enabled development.
By default, Synapse Studio uses Synapse live, as shown in Fig 1. With Synapse live you can't work in a group for the same codebase whereas by enabling Git collaboration, this becomes easy. This article will demonstrate a step-by-step guide to set up Git-enabled development in Synapse Studio.
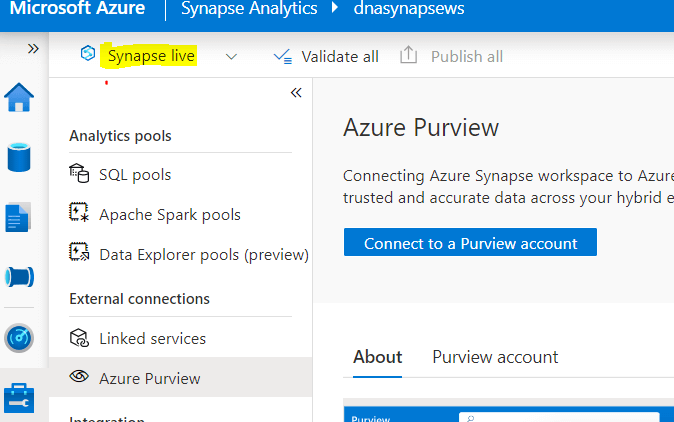
Fig 1: Synapse live
With the Git enabled development approach either you can use Azure DevOps Git or GitHub. This article will guide you using Azure DevOps Git integration.
Prerequisites
There are two prerequisites before following along with this article:
- Permissions - You must need to have contributor or higher role in the Synapse workspace to connect, edit or delete the source code repository.
- Git Repository - You also need to create the Git repository. You will find more details about creating an Azure DevOps repository in this link.
Choose from Two Different Options
There are two ways you can connect Azure DevOps Git from Synapse Studio, either from the global bar or from manage hub. You will find details below how to choose from the two options.
Option 1: The global bar
If you follow the figure 2, select the "Synapse live" drop down menu then you will find "Set up code repository". Choose this option.
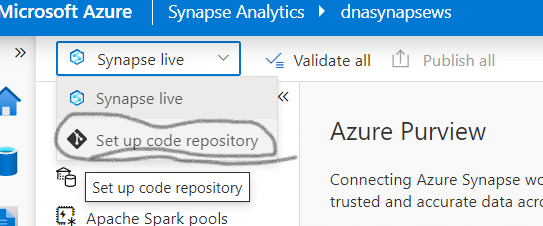
Fig 2: Setup code repo from global bar
Option 2: The Manage hub
From Synapse studio look at the left bottom menu, as shown in figure 3. Those the last icon that looks like a toolbox. This is the Manage selection. Then choose the Git configuration item int eh menu that is shown to the right of this icon. In the main pane, select configure.
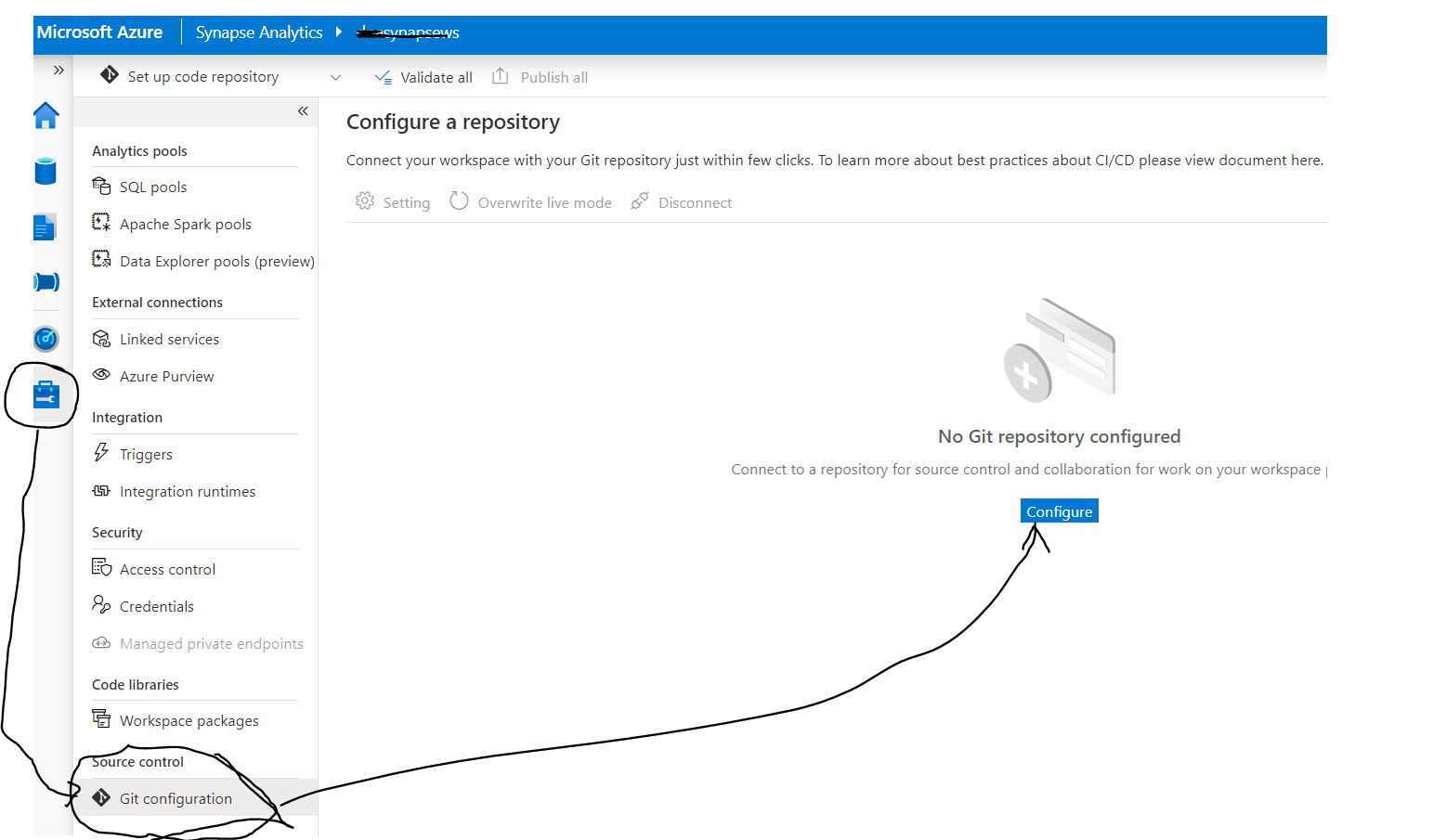
Fig 3: setup code repo from manage hub
Either of the the above two options will take you to the next step, which look like Fig 4. By selecting Azure DevOps Git you connect Azure DevOps Git with the Synapse Studio.
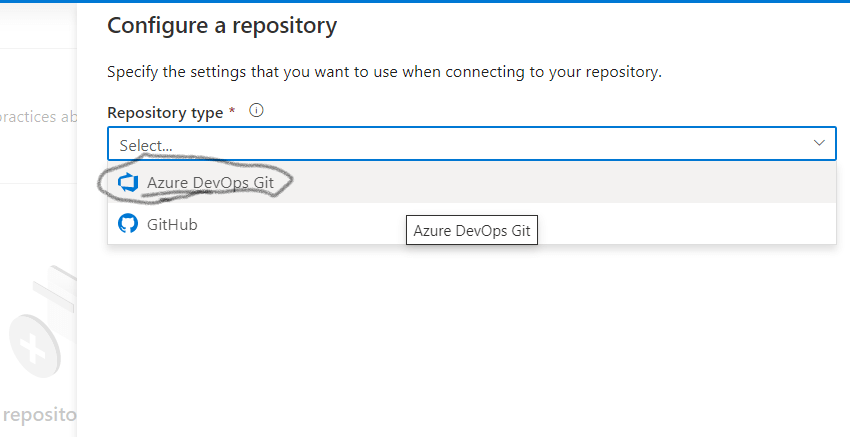
Fig 4: Choose either DevOps Git or Github
At the next step you will find one more attribute populated, as shown in the below figure 5. Please select the appropriate Azure Active Directory from your organization.
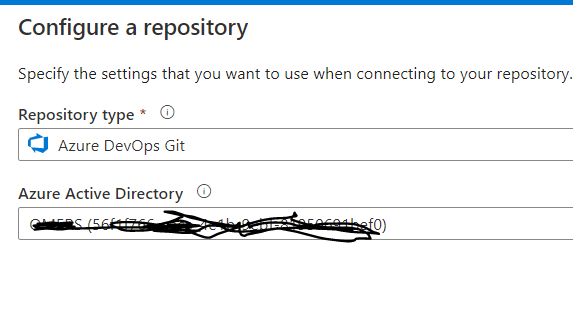
Fig 5: Connect the AD tenants
After clicking "Next" you will enter all the necessary information to choose your Git repository which is already created in your organization. Each item shown in Fig 6 is explained below:
- Azure DevOps Organization: In the dropdown you may find more than one organization please select the appropriate organization. It's organization name which have been created when Azure DevOps repository is configured.
- ProjectName: There are more than one project in the list, select the relevant one. This is Azure DevOps repos project name which you created earlier.
- RepositoryName: Please select the right repository from the list or you can also create a repository.
- Collaboration branch: By default, it's master. This is the branch where all other branch will be created from. Code will be merged to this branch from other branches as well as you will publish the code from this branch.
- Publish branch: The Publish branch is the branch in your repository where publishing related ARM templates are stored and updated. In general adf_publish is your publish branch but you can also make any other branch as a publish branch.
- Root folder: Your root folder in your Azure Repos collaboration branch.
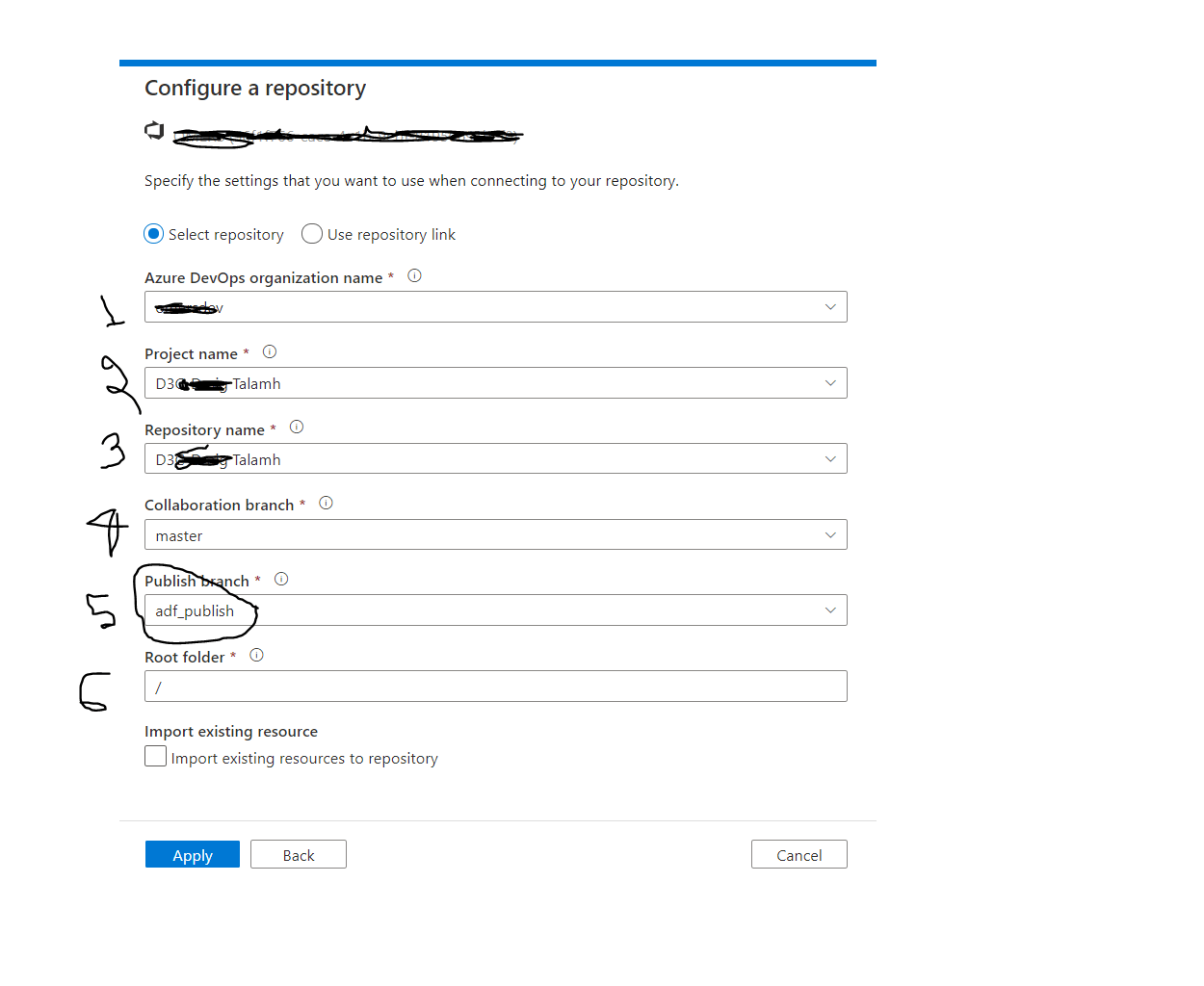
Fig 6: Configure repository
After completing all the above steps, click "Apply". When this process is successfully completed you should able to see the Git repository branches, as shown in Fig 7.
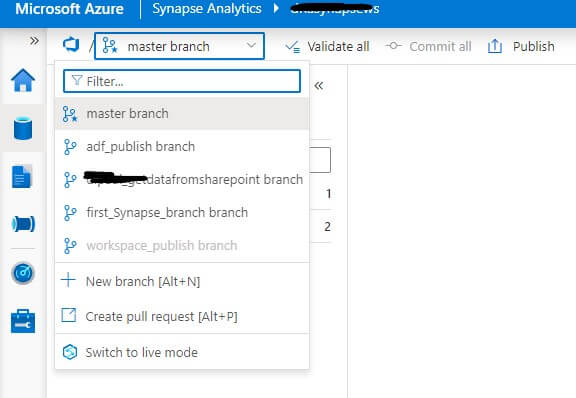
Fig 7: Synapse Studio after connecting with Azure DevOps Git
How to disconnect from Azure DevOps Git
To disconnect from Azure DevOps Git repo, you need to go to Manage-> Git configuration, as shown in Fig 8. There is a Disconnect menu item at the top.
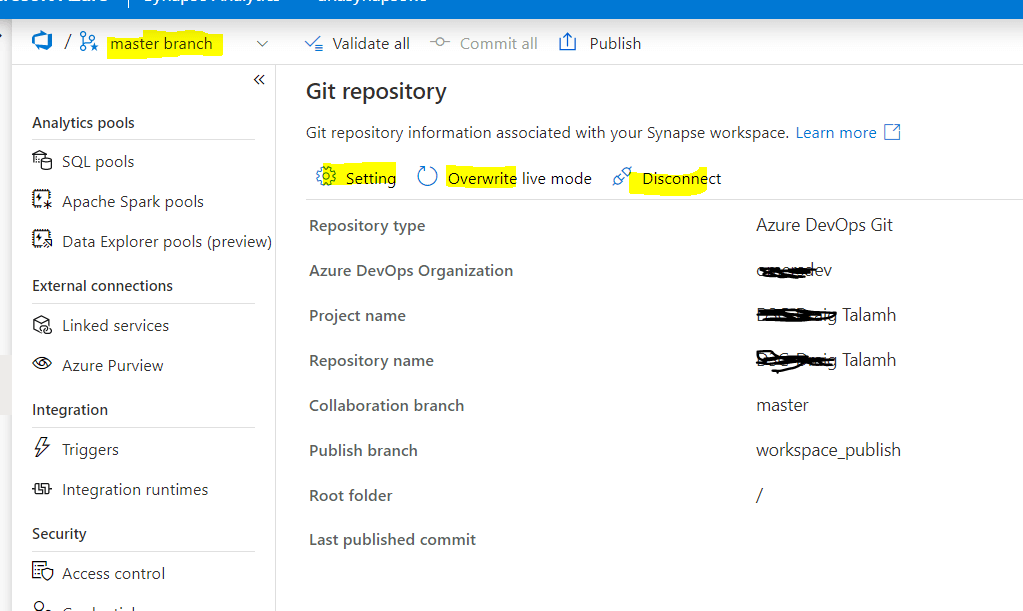
Fig 8: Disconnect from Azure DevOps Git Repo
Please note that "Disconnect" option will be disabled if you on any other branch than master. So, make sure you choose master branch if you need to disconnect the Azure DevOps Git Repo.
In summary, there are two ways to Develop and execute code in Azure Synapse and collaboration is only possible with Git enablement. The article depicted how to connect Azure DevOps Git with Azure Synapse Studio as well as how to disconnect them whenever required.