While you are working with data warehouse/ BI development, sometimes you may need to load data from API. The API can be RESTful or SOAP web service. However, this post cover how to load data from RESTful API which return a .JSON file and then insert the data from the .JSON file into a table in Data Warehouse.
Tool uses: Visual Studio 2017 Windows Application (C#), SSIS, MS SQL Server 2016 +
Steps includes:
1) Load data from Web API (REST) and save as .json file by using Visual Studio 2017 Windows Application (C#)
2) Insert data from the .json file to a table in data warehouse by using MS SSIS
Details of the steps are followings:
Step 1: Load data from Web API (REST) and save as .json file by using Visual Studio 2017 Windows Application (C#)
a) Create a visual studio solution by selecting Windows Form Apps under Windows Classic Desktop as like below figure 1.
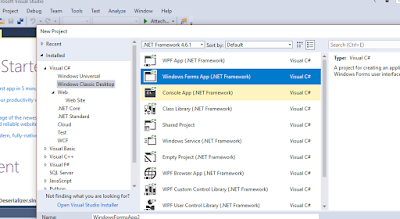 |
| Fig 1: Create VS solution to load data from Web API |
b) Code Behind to call web service and generate the .JSON file
Please copy the code and paste into your newly created project at the right place and change the URL for the API as suggested.
private void Form1_Load(object sender, EventArgs e)
{
try
{
var jsonData = readData();
}
catch (Exception ex)
{
throw ex;
}
}
private string readData()
{
try
{
string fileName = string.Format("{0}\\{1}", System.IO.Path.GetDirectoryName(Application.ExecutablePath), @"APIFile.json");
if (!writeByteInFile(fileName, downloadData()))
{
return string.Empty;
}
if (System.IO.File.Exists(fileName))
{
string text = System.IO.File.ReadAllText(fileName);
return text;
}
return string.Empty;
}
catch (Exception ex)
{
return string.Empty;
}
}
private byte[] downloadData()
{
WebClient request = new WebClient();
byte[] downloadData = request.DownloadData(@"https://ABCRestfulWebAPI" /*replace with your vendor provided web API*/
return downloadData;
}
private bool writeByteInFile(string fileName, byte[] byteArray)
{
try
{
if (System.IO.File.Exists(fileName))
{
System.IO.File.Delete(fileName);
}
using (var fs = new FileStream(fileName, FileMode.Create, FileAccess.Write))
{
fs.Write(byteArray, 0, byteArray.Length);
return true;
}
}
catch (Exception ex)
{
return false;
}
}
You will find the .json file loaded to the bin folder of the solution:
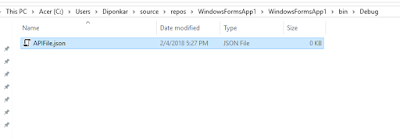 |
| Fig 2: Loaded .JSON file from the Web API |
Step 2: Insert data from the .json file to a table in the data warehouse by using MS SSIS
a) JSON data format : The JSON file that we downloaded by following step 1 is look like below fig:3
 |
| Fig 3: Read Json File |
b) Parse and Transform the JSON Data
We are fortunate enough that, from MS SQL Server 2016 and on ward Microsoft has JSON capabilities where you can parse and transform the JSON data to SQL table format.
Write the below query to parse the JSON data and transform as like SQL table data.
SELECT [date]
,[type]
,sender
,[subject]
,receiver
,[read]
FROM OPENROWSET (BULK 'C:\temp\APIFile.json', SINGLE_CLOB) as j
CROSS APPLY OPENJSON(BulkColumn, '$.results')
WITH ([date] date
,[type] nvarchar(20)
,sender nvarchar(100)
,subject nvarchar(200)
,receiver nvarchar(400)
,[read] bit
)
After running the above syntax you will find data like below:
 |
| Fig 4: After parsing JSON data it's exactly look like SQL table now |
c) Make a SSIS package to run End to End
At last, create a SSIS package and include following steps to load the data into the table
i ) Process task is running to execute the .exe file created via step 1
ii) Moving json file to other location (It's best to keep the imported file at one place, but it's not mandatory)
iii) Data flow task to read data from json file, parse and transform it and then load to the destination table (OLEDB source and OLEDB destination have been used to load the data to the table)
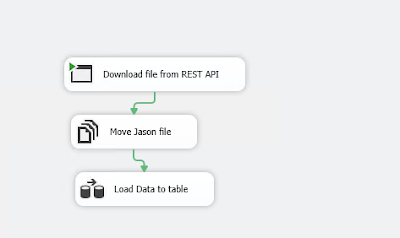 |
| Fig 5. How SSIS package will load data to the table |




































